blob: b4b0b2fa913f7feaa3f3692b5c531adab3e0086b (
plain)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# Performance
The image below shows the approximate performance of:
* `fpm` (the `Q16.16` type)
* [libfixmath](https://github.com/PetteriAimonen/libfixmath) (`fix16`), an alternative C library (see [notes](#notes)).
* [Compositional Numeric Library](https://github.com/johnmcfarlane/cnl) (`CNL`), an experimental library that is being developed in C++'s [SG14](https://github.com/WG21-SG14/SG14).
* native FPU operations (`float` and `double`).
The graph below plots the average number of nanoseconds a single operation takes: lower is better. The data was collected with [Google Benchmark](https://github.com/google/benchmark) on an Intel Core i7-5820K, 3.3GHz.
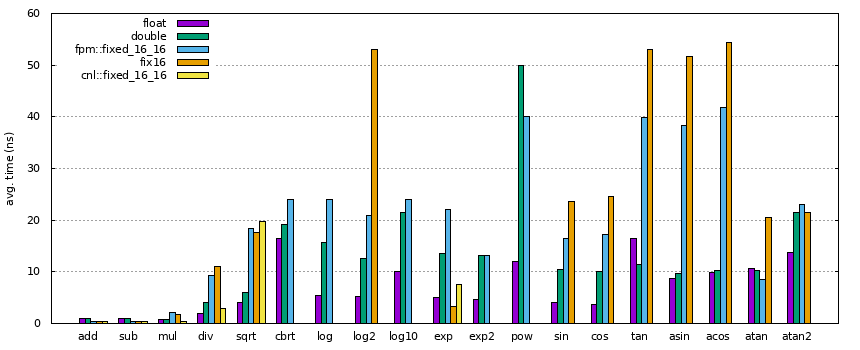
The results show the following:
* Compared to `libfixmath`, the performance of `fpm` is at least as good, except for `exp`, where it's considerably slower.
* Compared to CNL, `fpm` only matches the performance for `sqrt`. However, CNL does not support the majority of benchmarked functions.
* Compared to native single-precision floating-point operations, `fpm` is slower by up to an order of magnitude for most functions, except for the basic `add`, `sub` and several power or trigonometry functions, where it is faster.
## Notes
For a fair comparison, `libfixmath` was compiled with `FIXMATH_NO_CACHE`.
It should also have been compiled with `FIXMATH_NO_OVERFLOW` (since `fpm` does not detect overflow), but `libfixmath` failed to compile with that option.
|
